本文主要介绍Linux系统服务器的Slurm服务。
概述
Slurm 是一个开源的、容错的、高度可扩展的集群管理和作业调度系统,适用于大规模和小型的 Linux 集群。Slurm 在运行时不需对内核进行任何修改,并且相对自包含。
作为集群工作负载管理器,Slurm 主要有三个核心功能:
- 为用户分配一段时间内独占或非独占的资源(计算节点)访问权限,以便他们可以执行任务
- 提供了一个框架来启动、执行和监控分配给节点的工作(通常是并行作业)
- 通过管理待处理工作的队列来仲裁资源竞争。可选插件可用于计费、高级预约、并行作业的时间共享调度、回填调度、基于拓扑的资源选择、按用户或账户限制资源,以及复杂的多因素作业优先级算法。
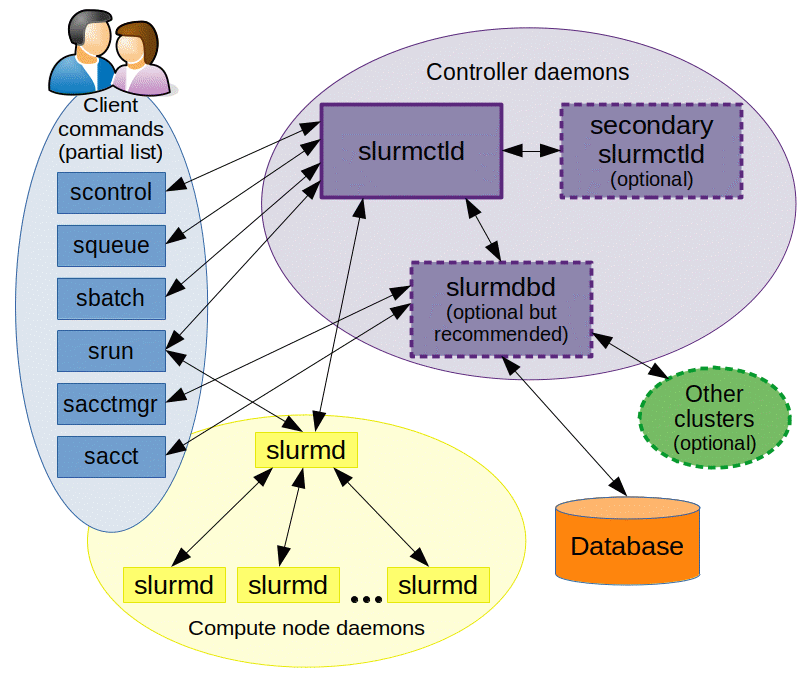
系统架构
Slurm 有一个中心管理器 slurmctld,负责监控资源和工作。还可以有一个备用管理器,在主管理器发生故障时接管职责。
每个计算服务器(节点)都有一个 slurmd 守护进程,类似于远程 shell:它等待工作,执行该工作,返回状态,然后等待更多工作。slurmd 守护进程提供了容错的层次化通信。
可选的 slurmdbd(Slurm 数据库守护进程)可以用于在一个数据库中记录多个 Slurm 管理集群的计费信息。
slurmrestd(Slurm REST API Daemon) 是可选的,用于通过 REST API 与 Slurm 交互。
用户工具如下,所有功能都有相应的API
srun用于启动作业scancel用于终止排队或正在运行的作业sinfo用于报告系统状态squeue用于报告作业状态sacct用于获取正在运行或已完成的作业和作业步骤的信息sview命令以图形方式报告系统和作业状态,包括网络拓扑scontrol是一个管理工具,用于监控和/或修改集群上的配置和状态信息sacctmgr是数据库管理工具,用于标识集群、有效用户、有效账户等。
术语
- 节点
- Head Node:头节点、管理节点、控制节点,运行slurmctld管理服务的节点。
- Compute Node:计算节点,运行作业计算任务的节点,需运行slurmd服务。
- Login Node:用户登录节点,用于用户登录的节点。
- SlurmDBD Node:SlurmDBD节点、SlurmDBD数据库节点,存储调度策略、记账和作业等信息的节点,需运行slurmdbd服务。
- 客户节点:含计算节点和用户登录节点。
- 用户
- account:账户,一个账户可以含有多个用户。
- user:用户,多个用户可以共享一个账户。
- bank account:银行账户,对应机时费等。
- 资源
- GRES:Generic Resource,通用资源。
- TRES:Trackable RESources,可追踪资源。
- QOS:Quality of Service,服务质量,作业优先级。
- association:关联。可利用其实现,如用户的关联不在数据库中,这将阻止用户运行作业。该选项可以阻止用户访问无效账户。
- Partition:队列、分区。用于对计算节点、作业并行规模、作业时长、用户等进行分组管理,以合理分配资源。
- socket:CPU插槽,可以简单理解为CPU。
- core:CPU核,单颗CPU可以具有多颗CPU核。
- job:作业。
- job step:作业步,单个作业(job)可以有个多作业步。
- tasks:任务数,单个作业或作业步可有多个任务,一般一个任务需一个CPU核,可理解为所需的CPU核数。
- rank:秩,如MPI进程号。
- partition:队列、分区。作业需在特定队列中运行,一般不同队列允许的资源不一样,比如单作业核数等。
- stdin:标准输入文件,一般指可以通过屏幕输入或采用 <文件名 方式传递给程序的文件,对应C程序中的文件描述符0。
- stdout:标准输出文件,程序运行正常时输出信息到的文件,一般指输出到屏幕的,并可采用
>文件名定向到的文件,对应C程序中的文件描述符1。 - stderr:标准出错文件,程序运行出错时输出信息到的文件,一般指也输出到屏幕,并可采用2>定向到的文件(注意这里的2),对应C程序中的文件描述符2。
插件
Slurm含有一些通用目的插件可以使用,采用这些插件可以方便地支持多种基础结构,允许利用构建块方式吸纳多种Slurm配置,主要包括如下插件:
记账存储(Accounting Storage):主要用于存储作业历史数据。当采用SlurmDBD时,可以支持有限的基于系统的历史系统状态。
账户收集能源(Account Gather Energy):收集系统中每个作业或节点的能源(电力)消耗,该插件与记账存储Accounting Storage和作业记账收集Job Account Gather插件一起使用。
通信认证(Authentication of communications):提供在Slurm不同组件之间进行认证机制。
容器(Containers):HPC作业负载容器支持及实现。
信用(Credential,数字签名生成,Digital Signature Generation):用于生成电子签名的机制,可用于验证作业步在某节点上具有执行权限。与用于身份验证的插件不同,因为作业步请求从用户的 srun 命令发送,而不是直接从slurmctld守护进程发送,该守护进程将生成作业步凭据及其数字签名。
通用资源(Generic Resources):提供用于控制通用资源(如GPU)的接口。
作业提交(Job Submit):该插件提供特殊控制,以允许站点覆盖作业在提交和更新时提出的需求。
作业记账收集(Job Accounting Gather):收集作业步资源使用数据。
作业完成记录(Job Completion Logging):记录作业完成数据,一般是记账存储插件的子数据集。
启动器(Launchers):控制srun启动任务时的机制。
消息传递接口(MPI, Massage Passing Interface):针对多种MPI实现提供不同钩子,可用于设置MPI环境变量等。
抢占(Preempt):决定哪些作业可以抢占其它作业以及所采用的抢占机制。
优先级(Priority):在作业提交时赋予作业优先级,且在运行中生效(如,它们生命期)。
进程追踪(Process tracking,为了信号控制):提供用于确认各作业关联的进程,可用于作业记账及信号控制。
调度器(Scheduler):用于决定Slurm何时及如何调度作业的插件。
节点选择(Node selection):用于决定作业分配的资源插件。
站点因子(Site Factor,站点优先级):将作业多因子组件中的特殊的site_factor优先级在作业提交时赋予作业,且在运行中生效(如,它们生命期)。
交换及互联(Switch or interconnect):用于网络交换和互联接口的插件。对于多数网络系统(以太网或InifiniBand)并不需要。
作业亲和性(Task Affinity):提供一种用于将作业和其独立的任务绑定到特定处理器的机制。
网络拓扑(Network Topology):基于网络拓扑提供资源选择优化,用于作业分配和提前预留资源。
Slurm 的配置与管理
- Slurm 的配置文件
- 配置文件结构
- 常用配置选项
- Slurm 的安装与启动
- 安装步骤
- 启动与停止服务
- Slurm 的管理工具
- scontrol 的使用
- sacctmgr 的功能
- sview 的图形展示
Slurm 的使用指南
作业提交
- salloc :为需实时处理的作业分配资源,提交后等获得作业分配的资源后运行,作业结束后返回命令行终端。
- sbatch :批处理提交,提交后无需等待立即返回命令行终端。
- srun :运行并行作业,等获得作业分配的资源并运行,作业结束后返回命令行终端。
批处理作业(采用 sbatch 命令提交,最常用方式)
对于批处理作业(提交后立即返回该命令行终端,用户可进行其它操作)使用 sbatch 命令提交作业脚本,作业被调度运行后,在所分配的首个节点上执行作业脚本。在作业脚本中也可使用 srun 命令加载作业任务。提交时采用的命令行终端终止,也不影响作业运行。
交互式作业提交(采用 srun 命令提交)
资源分配与任务加载两步均通过 srun 命令进行:当在登录shell中执行 srun 命令时, srun 首先向系统提交作业请求并等待资源分配,然后在所分配的节点上加载作业任务。采用该模式,用户在该终端需等待任务结束才能继续其它操作,在作业结束前,如果提交时的命令行终端断开,则任务终止。一般用于短时间小作业测试。
实时分配模式作业(采用 salloc 命令提交)
分配作业模式类似于交互式作业模式和批处理作业模式的融合。用户需指定所需要的资源条件,向资源管理器提出作业的资源分配请求。提交后,作业处于排队,当用户请求资源被满足时,将在用户提交作业的节点上执行用户所指定的命令,指定的命令执行结束后,作业运行结束,用户申请的资源被释放。在作业结束前,如果提交时的命令行终端断开,则任务终止。典型用途是分配资源并启动一个shell,然后在这个shell中利用 srun 运行并行作业。
salloc 后面如果没有跟定相应的脚本或可执行文件,则默认选择 /bin/sh ,用户获得了一个合适环境变量的shell环境。
salloc 和 sbatch 最主要的区别是 salloc 命令资源请求被满足时,直接在提交作业的节点执行相应任务,而 sbatch 则当资源请求被满足时,在分配的第一个节点上执行相应任务。
salloc 在分配资源后,再执行相应的任务,很适合需要指定运行节点和其它资源限制,并有特定命令的作业。
作业管理
- squeue :查看作业信息
- scancel :取消作业
- scontrol :查看作业、节点和队列等信息
资源查询
- sacctmgr: 服务质量(QoS)
- sacct: 获取记账信息
规划准备
- 集群名:MyCluster
- 管理节点(c1):
- IP:192.168.5.67
/public目录:通过NFS网络共享给其它节点使用- 配置文件:
/etc/slurm/目录下的cgroup.conf、slurm.conf、slurmdbd.conf等文件 - 需要启动(按顺序)的守护进程服务: 通信认证(munge), 系统数据库(mariadb), Slurm数据库(slurmdbd), 主控管理器(slurmctld)
- 计算节点(c2, c3)
- IP:192.168.5.67
/public目录:通过NFS网络共享给其它节点使用- 需要启动(按顺序)的守护进程服务: 通信认证(munge), Slurm数据库(slurmdbd)
Master
设置通讯所需的munge服务
- 安装MUNGE
# 安装MUNGE进行身份验证
yum -y install munge munge-libs munge-devel
# 安装rng-tools来正确创建密钥
yum install rng-tools -y
Slurm常见错误与解决方法
fatal: Unable to initialize accounting_storage plugin
- 查看
/etc/slurm/slurm.conf文件关于accounting_storage部分
# ACCOUNTING
AccountingStorageType=accounting_storage/filetxt
#AccountingStorageHost=
AccountingStorageLoc=/public/slurm
#AccountingStoragePass=
#AccountingStorageUser=
- 修改
/etc/slurm/slurm.conf文件
...
AccountingStorageLoc=/public/slurm/acct
...
- 创建相关的文件
[root@c1 ~]# touch /public/slurm/acct
- 更新并查看
slurmctld服务
[root@c1 ~]# systemctl restart slurmctld
[root@c1 ~]# systemctl status slurmctld
Nodes required for job are DOWN, DRAINED or reserved for jobs in higher priority partitions
- 编写作业
jobsubmit.sh
#!/bin/bash
#SBATCH -J test # test
#SBATCH -o test.out # test.out
#SBATCH -N 1 # 1
#SBATCH --ntasks-per-node=1 # 1
#SBATCH --cpus-per-task=4 # CPU 4
#SBATCH -t 1:00:00 # 1
# 加载运行环境
module add intel-2018 # intel
# 执行命令
python test.py
test.py
# test.py
print("test start")
for i in range(10):
print(f"test current {i=}")
print("test end")
- 提交作业
[slurm@c1 ~]$ sbatch jobsubmit.sh
- 查看队列和节点信息
[slurm@c1 ~]$ squeue
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
43 all test slurm PD 0:00 1(Nodes required for job are DOWN, DRAINED or reserved for jobs in higher priority partitions)
[slurm@c1 ~]$ sinfo
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST
all* up infinite 2 drain c[1-2]
- 取消作业
[slurm@c1 ~]$ scancel 43
- 恢复节点状态
[slurm@c1 ~]$ scontrol update NodeName=c[1-2] State="IDLE"
[slurm@c1 ~]$ sinfo
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST
all* up infinite 2 idle c[1-2]
Additional Resources
Documentation
Useful Websites
1.
- Slurm Accounting Storage 配置
- Slurm安装4之slurm安装
- slurm集群安装与踩坑详解
- CentOS 7 安装Slurm
- Nodes required for job are DOWN, DRAINED or reserved for jobs in higher priority partitions